HELIOS PDF Handshake 2.0 Benutzerhandbuch |
||||
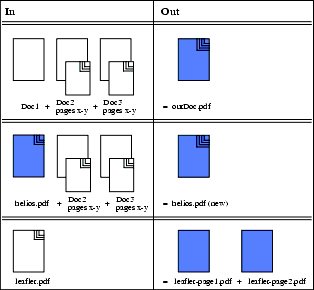
Das "pdfcat"-Programm ermöglicht Ihnen auf dem Server PDF-Dateien in einzelne Seiten aufzuteilen oder mehrere PDF-Seiten zu einer Datei zusammenzufügen. Die Verwendung von "pdfcat" ist unentbehrlich, wenn Sie ein mehrseitiges Dokument haben, welches Sie in einem reinen EPSF- oder OPI-Workflow einsetzen wollen. Der OPI Server erzeugt immer nur von der ersten Seite eines PDF-Dokuments ein Platzierungsbild. Wenn Sie also ein Platzierungsbild von der zweiten Seite eines Dokuments haben möchten, müssen Sie die gewünschte Seite extrahieren und als neue Einzelseiten-PDF-Datei sichern. Die nachfolgende Grafik zeigt die drei verschiedenen Programmmodi, die alle unabhängig voneinander sind und sich gegenseitig ausschließen: Der "Zusammenfügen"-Modus verbindet die ausgewählten PDF-Dateien (oder Teile davon) zu einer neuen Datei, der "Anhängen"-Modus hängt die ausgewählten Dateien (oder Teile davon) an eine bestehende Datei an und der "Extraktions"-Modus schreibt die ausgewählten Seiten eines existierenden Dokuments in neue Einzelseitendateien.
Jede PDF-Datei enthält eine Liste von Dateiinformationen, wie z.B. Verfasser, Erstellungsdatum, Änderungsdatum, Bildprofile (optional). Außerdem kann eine PDF-Datei Sicherheitseinstellungen beinhalten (optional), eine Liste von Lesezeichen (Inhaltsverzeichnis) und Anmerkungen wie Textfelder, Knöpfe usw.
Das "pdfcat"-Programm organisiert und erstellt PDF-Dateien neu. Dabei werden die Dateiinformationen, Profile, Sicherheitseinstellungen, Lesezeichen und Anmerkungen wie folgt behandelt:
- Wenn "pdfcat" ein neues mehrseitiges Dokument erstellt - wie in der ersten Zeile der oberen Abbildung gezeigt - erhält die neue Datei ihren eigenen Verfasser und ein Erstellungsdatum. Sie wird keine Profile haben, auch wenn die Ursprungsdateien "getagged" waren, und sie wird keine Sicherheitseinstellungen haben. Lesezeichen - falls in den Ursprungsdateien vorhanden - werden nicht in die neue Datei kopiert. Anmerkungen werden aus den ursprünglichen Dateien in das neuerzeugte Dokument übernommen.
- Wenn "pdfcat"-Seiten und/oder Dokumente an eine bestehende PDF-Datei anhängt - wie in der zweiten Zeile der oberen Abbildung gezeigt -, wird die Zieldatei (hier: "helios.pdf(new)") alle Informationen enthalten, die schon in der Ursprungsdatei enthalten waren (hier: "helios.pdf"). Dateiinformationen, Profile, Sicherheitseinstellungen, Lesezeichen und Anmerkungen bleiben unverändert. Informationen, die in den angehängten Dateien enthalten waren (hier: "Doc"2 und "Doc3") werden mit Ausnahme der Anmerkungen nicht in die Zieldatei übernommen sondern ignoriert.
- Wenn "pdfcat" ein Dokument in mehrere neue aufteilt - wie in der letzten Zeile der obigen Abbildung gezeigt -, erben die neuen Einzelseitendokumente die Dateiinformationen, Profile, Anmerkungen und Sicherheitseinstellungen von der Originaldatei. Lesezeichen werden jedoch nicht in die Zieldateien kopiert. Bitte beachten Sie, dass "pdfcat" keine Kommentare in die Finder-Information schreiben kann. Wenn die PDF-Dateien Profilinformationen enthalten, werden diese üblicherweise im Textfeld Kommentar: der Macintosh Finder Information aufgelistet (vergl. Abb. 11 in Kapitel 5 "Bevor Sie beginnen"). Dieses Textfeld kann leer sein, wenn Sie PDF-Dateien mit "pdfcat" erstellt haben, auch wenn die neuen Dateien Profilinformationen enthalten. In diesem Falle können Sie unser Acrobat Druck-Plugin oder das EtherShare OPI "Tagger"-Programm benutzen, um Profile sichtbar zu machen.
Für PDF-Dateien, die mit "pdfcat" erstellt wurden, funktioniert die automatische Layouterzeugung nicht. Sie müssen unser "touch"-Hilfsprogramm oder das UNIX-Layoutprogramm auf dem Server nutzen, um Platzierungsbilder von den neuen PDF-Dateien zu erzeugen.
fügt existierende PDF-Dokumente (inDocs...) zu einem neuen PDF-Dokument (outDoc) zusammen. Mit diesem Parameter müssen Sie einen Zieldateinamen und einen oder mehrere Ursprungsdateinamen bestimmen. Es ist möglich, nur ausgewählte Seiten von der Ursprungsdatei zur Zieldatei zu kopieren, indem Sie Seitenbereiche angeben. Gültige Seitenbereiche sind im Abschnitt "Seitenbereiche" weiter unten aufgeführt.
Wichtig: Wenn der Name, den Sie für die Zieldatei auswählen, bereits im Zielverzeichnis vorhanden ist, wird die vorhandene Datei ersetzt.
hängt ein oder mehrere PDF-Dokumente oder Teile davon (,inDocs...") an das Ende eines anderen - schon bestehenden - PDF-Dokuments (,outDoc") an.
kopiert entweder alle Seiten oder die Seiten, die Sie bestimmt haben, aus einem PDF-Dokument heraus und erstellt neue Einzelseiten-PDF-Dateien. Bei der Anwendung dieses Parameters müssen Sie ein Prefix für die Zieldateien angeben. Die Seiten mit den Seitenzahlen <nnn> der Ursprungsdatei werden dann in ein neues PDF-Dokument mit dem Namen "<prefix><nnn>.pdf" kopiert.
Hinweis: Die anzugebenden Dateinamen dürfen auch komplette UNIX-Pfadnamen enthalten, die auf ein anderes Verzeichnis verweisen.
Nach jeder "inDoc"-Angabe kann eine durch Komma getrennte Liste von Bereichsfestlegungen folgen. Auf diese Weise können Sie sicherstellen, dass nur die vorher festgelegten Seiten auf dem Ursprungsdokument genutzt werden.
- 2 (nutzt nur Seite 2 von inDoc)
- -11 (nutzt Seite 1 bis 11)
- 11- (nutzt Seite 11 bis zur letzten Seite)
- 2-11 (nutzt Seite 2 bis 11 - nimmt Seite 2 zuerst)
- 11-2 (nutzt auch Seite 2 bis 11 - aber in umgekehrter
Reihenfolge)- \$-11 (nutzt letzte Seite bis Seite 11. Das "$"-Zeichen
steht für die letzte Seite im Dokument; in einer
UNIX-Shell müssen Sie "\$" eingeben.)Sie können mehrere - durch Komma getrennte - Anordnungen auf einmal bestimmen (z.B. inDoc.pdf,3-6,12-). Geben Sie aber bei einer solchen Festlegung keine Leerzeichen ein.
schreibt alle Seiten des Dokuments "doc1.pdf" und dann die Seiten 2, 5, 6, 7 von Dokument "doc2.pdf" in ein neues Dokument mit Namen "new.pdf".
schreibt alle Seiten von Dokument "doc1.pdf" in umgekehrter Reihenfolge in ein neues Dokument mit Namen "new.pdf".
| © 2002 HELIOS Software GmbH |